 My interest in computer generated images and animation goes back to when I was in my 9th grade. Our computer teacher (Miss. Banurekha) wanted me and my dear friend Siddharth Choraria to participate in an inter-school computer graphics competition. I wasn’t any computer rock-star, but she had seen my pencil-sketches on the class notice board and thought that we do something useful. Of course, Siddharth was a brilliant student and we worked well together.
My interest in computer generated images and animation goes back to when I was in my 9th grade. Our computer teacher (Miss. Banurekha) wanted me and my dear friend Siddharth Choraria to participate in an inter-school computer graphics competition. I wasn’t any computer rock-star, but she had seen my pencil-sketches on the class notice board and thought that we do something useful. Of course, Siddharth was a brilliant student and we worked well together.
We spent several days and nights on the project. We had decided to portray a short story about the inevitable effects of war on human society. After I drew each scene on a graph paper, we manually transferred the co-ordinates (of the best-fit lines approximating the curves in the image) to the computer and drew on it using GW BASIC. There was no concept of key-framing, so we redrew each frame repeatedly, changing only the portions required for creating the animation. We also had no idea that we could use matrices multiplications to transform objects in CG.
Since then I have been very interested in computer graphics. However, I never really took the deep plunge to explore the CG world. So, when the opportunity to learn modern computer graphics from one of the world’s best known professors of CG, Prof. Ravi Ramamoorthi, came in the form of a MOOC course (Foundations of Computer Graphics BerkeleyX), I just couldn’t resist. My main motivation for the course was not only to make pretty (CG) pictures, but also to learn 3D geometry used in CG, ray-tracing and OpenGL so that I could use them in other areas such as computational imaging, scientific computation and visualization. I also wanted to know how people create photo-realistic effects.
The course required a lot of work, and it took way more time and effort than I had thought it would take. The 6-week course gave a very nice overview of the CG field. At the same time the assignments were based on some fundamental concepts. In the end, I admit that I have learned quite a lot of interesting things that I can now put to good use in other areas.
The first two assignments, based on OpenGL rendering, were relatively easy. We were given the basic code, and had to really program only the essential parts/concepts that the assignments were addressing. For the last assignment, we had to build our own recursive ray-tracing program. With all the discussion at the course forum, the lecture videos, and some resources on the internet, I was able to code my own basic ray-tracer using C++. Here is an image generated using the ray-tracer. It is very basic and has hard-edge shadows. It also doesn’t have any texture mapping code at this point. Also, the camera doesn’t have any depth-of-field yet, but it is not that hard to add.

Stanford dragon in Cornell Box. Rendered using basic recursive ray-tracing.
The dragon in the rendered image is the very well-known “Stanford dragon” from the Stanford 3D Scanning Repository. The original file contains 871,414 triangular faces made from 437,645 vertices. The dragon rendered here is made from a reduced polygonal mesh containing 100,000 triangular faces from 50,001 vertices. The figures below show the polygonal mesh model of the dragon. The 3D triangular mesh was generated using a surface reconstruction algorithm from a point cloud of the 3D coordinates which was gathered using optical triangulation technique using a swept-stripe 3D laser scanner (More about this fascinating process on some other day).

3D polygonal mesh of the Stanford dragon.
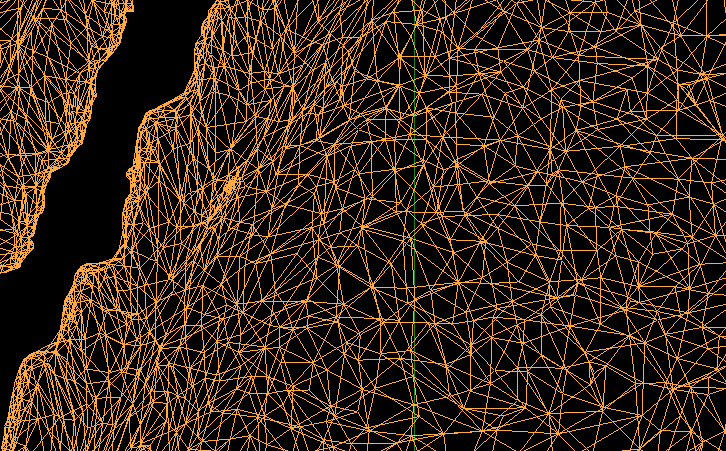
Closeup of a section of the polygon mesh of the Stanford Dragon

Zoomed-in section of the poly mesh. (The poly mesh in blue-green color has been overlaid on top of the triangles).
During the course, I made a couple of mind-maps (using Docear, a free and open source mind-mapping tool) to gather information about the field. The mind-maps are not complete, and they never will be. I will keep updating them as I learn more and more about CG. I have shared them here (please feel free to download them and use them as you like). The figure below is a partial snap-shot of the mind-map.

Partial snap-shot of one of the mind maps.
The computer graphics program back in my 9th grade contained 5 minutes of animation which really impressed the judges, and they were more than glad to hand over the first position to us. I hope, now that I am re-exposed to CG, I will continue to improve my basic ray-tracing program, and add features like depth-of-field, multiple rays/samples per pixel, anti-aliasing, path tracing, photon-mapping, global-illumination and the list of “hacks” really goes on and on.

I downloaded the Docear recently. Its really good. Thanks lot for the post.
i was hoping to go into game programming ….. you think this course will benefit me ??
Hi Anupam,
I absolutely think that the fundamentals that you learn in this course will help you from the “graphic” aspects of things, and also appreciate and understand your tools better. Also, I would like to add that you can get the maximum out of this course (in order to finish the 3rd assignment on building your own ray-tracing system from scratch), if you know some amount of C++ programming. (At the same time, I do know a few people who design great games and graphics using Blender without knowing the math, or programming).